Autograd (自动求导)
译者:@unknown
校对者:@bringtree
Autograd 现在是 torch 自动微分的核心包 . 它是使用基于 tape 的系统来进行自动微分的.
在前向阶段, autograd tape 会记住它执行的所有操作, 在反向阶段, 它将重放这些操作
Variable (变量)
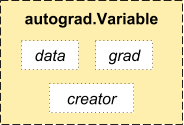
在 autograd 中, 我们引入了一个 Variable 类, 它是一个非常单薄 的 Tensor 包装器. 你可以通过 .data 访问到原始 tensor, 并在计算完反向之后, 求出这个变量的梯度, 并将这个梯度累加到 .grad 属性中.
Variable
还有一个对于 autograd 的使用非常重要的类 - Function 类. Variable 和 Function 是相互关联的, 并创建了一张无环图, 它记录一个完整的计算历史. 每个 Variable 的 .grad_fn 属性都引用了一个计算出这个Variable的函数 (除了用户创建的变量外 - 这些变量的 .grad_fn 为 None ).
如果你想要计算导数, 你可以在 Variable 上调用 .backward(). 如果 Variable 是一个标量 (i.e. 它拥有一个tensor元素), 则不需要为 backward() 指定任何参数, 但是如果它包含许多的元素, 则需要指定一个 grad_output 参数, 来匹配 tensor 的 shape.
import torch
from torch.autograd import Variable
x = Variable(torch.ones(2, 2), requires_grad=True)
print(x) # 注意 "Variable containing" 行
print(x.data)
print(x.grad)
print(x.grad_fn) # 我们自己创建的 x
对 x 做一个操作:
y = x + 2
print(y)
y 是由前面计算返回的结果创建的, 因此它有一个 grad_fn
print(y.grad_fn)
对 y 做更多的操作:
z = y * y * 3
out = z.mean()
print(z, out)
梯度
现在, 让我们来反向传播, 并打印出 d(out)/dx 的梯度
out.backward()
print(x.grad)
在默认情况下, 梯度计算会刷新计算图中包含的所有内部缓冲区, 所以如果您想要在图的某个部分向后执行两次梯度计算,则需要在 第一次传递过程中设置参数为 retain_variables = True.
x = Variable(torch.ones(2, 2), requires_grad=True)
y = x + 2
y.backward(torch.ones(2, 2), retain_graph=True)
# retain_variables 标志将阻止内部缓冲区被释放
print(x.grad)
z = y * y
print(z)
只是反向传播随机梯度
gradient = torch.randn(2, 2)
# 如果我们没有指定我们想保留变量, 这将会失败
y.backward(gradient)
print(x.grad)
